Hourglass
文章目录
Stacked Hourglass Networks for Human Pose Estimation
…
3 Network Architecture
3.1 Hourglass Design
hourglass的设计受启发于捕获不同尺度信息的需求,虽然局部证据对于识别面部或手部等特征至关重要,但最终的姿态估计需要对整个身体有一致的理解。人的方位,四肢的排列,以及相邻关节的关系是在图像中以不同尺寸最佳识别的众多线索之一。hourglass是一个简单的最小设计,并有能力捕获所有这些特征并将它们组合在一起以输出像素级预测。
网络必须有一些机制来有效处理和跨比例整合特征,一些方法使用几个分离的pipeline来处理此问题,即在多种分辨率下独立处理图像,然后在网络上组合这些特征。然而,我们选择使用带有skip layer的单个pipeline在每个分辨率上保持空间信息,该网络达到$4\times 4$像素的最低分辨率,从而允许使用较小的空间过滤器以比较图像整个空间的特征。
hourglass的设置如下:用卷积层和最大池化层处理特征使其下降到非常低的分辨率,在每个最大池化阶段,网络分出支路并以原始的池化前的分辨率应用更多卷积。在达到最低分辨率后,网络开始进行自上而下的上采样和跨尺度特征组合的过程。为了组合两个相邻分辨率的信息,我们根据Tompson等人描述的过程对较低分辨率做最邻近上采样,然后对两组特征逐元素相加。hourglass的拓扑是对称的,因此在向下的路径中的每一层都存在一个向上的对应层。
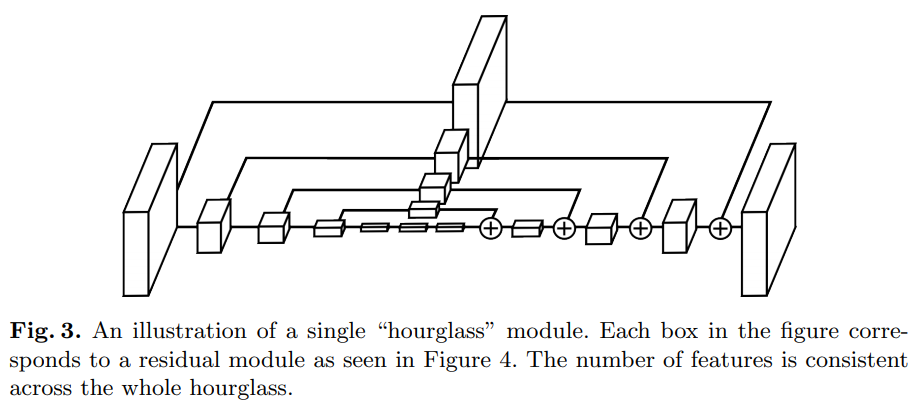
达到网络输出分辨率后,应用两个连续的$1\times1$卷积来产生最后的网络预测。网络的输出是一组heatmap,其中对于给定的heatmap,网络可预测每个像素点关节存在的概率。Fig.3阐述了整个模型(不包括最后的$1\times1$层)。
3.2 Layer Implementation
在保持hourglass整体形状的同时,层的特定实现仍具有一定灵活性。不同的选择会对网络的最终性能和训练产生适度的影响,我们探索了网络中层设计的几个选择。最近的研究已表明用$1\times1$卷积进行降维步骤的价值,以及用连续的较小过滤器捕获较大空间上下文的好处,比如我们可以将$5\times5$的过滤器用两个独立的$3\times3$的过滤器来代替。我们测试了整个网络设计,根据这些观点交换了不同的层模块。从大过滤器且没有reduction step的标准卷积层切换到更新的方法(像He等人提出的残差学习模块和基于“Inception”的设计)之后,我们经历了网络性能的提升。在使用这些类型的设计进行初步的性能提升之后,对层进行的各种其他探索和修改几乎无法进一步提高性能或训练时间。
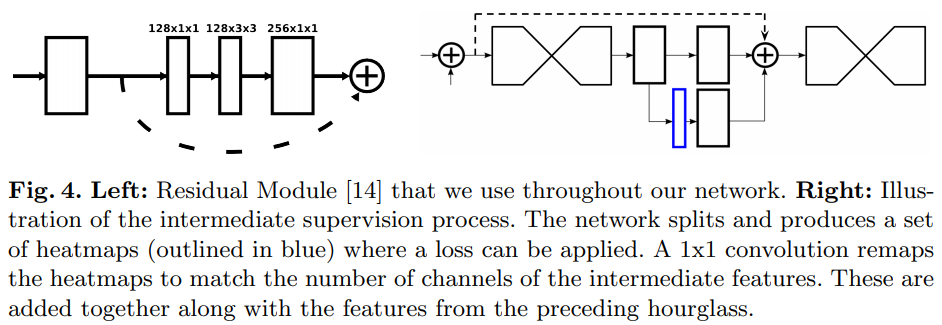
我们的最终设计充分利用了残差模块,从不使用大于$3\times3$的过滤器,并且瓶颈(bottlenecking)限制了每一层的参数总量,从而限制了总内存的使用。Fig.4显示了网络所使用的该模型,为了将其纳入整个网络设计的范围,Fig.3中的每个方框代表一个残差模块。
以$256\times256$的全输入分辨率运行需要大量的GPU内存,所以hourglass的最高分辨率(因此最终输出分辨率)为$64\times64$,这并不影响网络产生精确的关节预测的能力,整个网络以步长为2的$7\times7$的卷积层开始,后接一个残差模块和一轮最大池化以将分辨率从$256$降为$64$,Fig.3所示的hourglass之前有两个后续的残差模块。在整个hourglass中,所有的残差模块都输出256维特征。
3.3 Stacked Hourglass with Intermediate Supervision
我们通过以端对端的方式堆叠多个hourglass,将一个的输出投入下一个作为输入,来进一步加深网络架构。这为网络提供了一种重复的自下而上,自上而下的推理机制,从而允许重新评估整个图像的初始估计和特征。该方法的关键是中间heatmap的预测,我们可以对其应用损失。预测是在通过每个hourglass之后生成的,在hourglass中网络有一次机会在局部和全局范围内处理特征,后续的hourglass模块允许再次处理这些高级特征,以进一步评估更高阶的空间关系。这类似于其它的姿态估计方法,这些方法在多个迭代阶段和中间监督下表现出强大的性能。
考虑到仅使用单个hourglass模块进行中间监督的局限,在pipieline中生成初始预测集的合适位置是什么?大多数高阶特征仅在较低的分辨率下存在,除了最后的上采样出现的时候。如果在网络在进行上采样之后提供监督,则无法在较大的全局范围内以相对于彼此的方式重新评估这些特征。如果我们希望网络最佳地优化预测,则不能仅在局部范围内评估这些预测,与其他关节预测之间的关系以及整体背景和对完整图像的理解至关重要。在池化之前在pipeline的较早阶段应用监督是有可能的,但是在这一点上,给定像素的特征是处理相对局部的感受野的结果,因此不了解关键的全局线索。
重复的自下而上,自上而下的推理与堆叠的hourglass缓解了这些问题。每个hourglass都集成了局部和全局线索,要求网络产生早期预测需要它仅在整个网络的中途对图像有一个高层次的理解。后续阶段的自下而上,自上而下的处理允许更深地重新考虑这些特征。
在尺寸之间来回移动的这种方法特别重要,因为保留特征的空间位置对于最终的定位阶段至关重要。关节的精确位置是网络做出其他决定所必不可少的线索。对于诸如姿势估计之类的结构化问题,输出是许多不同特征的相互作用,应将这些特征放在一起以形成对场景的连贯理解。矛盾的证据和解剖学上的不可能性(contradicting evidence and anatomic impossiblity)是在沿线某处的一个错误导致的,通过在网络中来回移动可以保持精确的局部信息,然后重新考虑特征的整体一致性。
我们将中间预测重新集成到特征空间,方法是将它们映射到具有额外1x1卷积的大量通道。这些将增加到hourglass的中间特征以及上一阶段hourglass的输出特征(可视化见Fig.4),结果输出直接用作下一个hourglass模块的输入,该hourglass模块生成另一组预测。在最终的网络设计中,使用了八个hourglass。值得注意的是,hourglass模块之间没有共享权重,并且使用相同的gt将损失应用于所有hourglass的预测。损失和gt的详细信息将在下面描述。
3.4 Training Details
我们在两个基准数据集上评估我们的网络,FLIC和MPII Human Pose。前者包含从电影中取出的5003张图像(3987张训练,1016张测试),图像标注在上身,大多数人物正对着相机。MPII Human Pose包含约25k张多人标注图像,提供40k标注样本(28k训练,11k测试),没有提供测试标注,因此在所有的实验中,我们在训练图像的子集上进行训练,同时对约3000个样本的验证集进行评估。MPII包含从各种各样的人类活动中拍摄的图像,这些图像具有一系列具有挑战性的广泛表达的全身姿态。
…
与Tompson等人使用的的相同技术被用于监督,应用均方误差MSE损失将预测的heatmap与以关节位置为中心的2D高斯(标准偏差为1px)组成的真实heatmap进行比较。为了提高性能,在高精度的阈值时,在转换回图像的原始坐标空间之前,预测值会在其下一个最高相邻像素的方向上偏移四分之一像素。在MPII Human Pose中,某些关节没有相应的gt标注,在这些情况下,关节要么被截断,要么被严重遮挡,因此为进行监督,提供了全零的gt heatmap。
4 Results
…
文章作者 ling
上次更新 2019-09-28