PSMNet & SPP
文章目录
Pyramid Stereo Matching Network
1. Introduction
立体图像的深度估计对计算机视觉应用是有必要的,包括车辆自动驾驶,3D模型重建,以及目标检测和识别。给出一对矫正的立体图像,深度估计的目标是为参考图像的每个像素计算视差$d$,视差是指左右图像上一对对应像素之间的水平位移,对于左图的的像素$(x,y)$,如果其对应点在右图的$(x-d,y)$处,那么此像素的深度的计算方式为:$\frac{fB}{d}$,其中f是相机的焦距,B是两相机中心的距离。
立体匹配的典型pipieline包括基于匹配成本和后处理的对应点(corresponding points)的发现。最近,MC-CNN应用CNN去学习怎么匹配对应点,早期使用CNN的方法将对应估计(correspondence estimation)问题视为相似度计算,其中CNN计算一对图像块的相似度得分以进一步确定它们是否匹配。尽管CNN在准确性和速度方面与传统方法相比产生了显着的收获,但在遮挡区域,重复图案,无纹理区域和反射表面等固有病态区域很难找到精确的对应点。仅在不同视线点之间应用强度一致性约束通常不足以在这种不适合区域进行准确的对应估计。因此,来自全局上下文信息的区域支持必须被合并到立体匹配。
…
主要贡献: - 提出了用于无需后处理的立体匹配的端对端学习框架。 - 引入了金字塔池化模块,以将全局上下文信息合并到图像特征。 - 提出了堆叠的hourglass 3D CNN,以扩展cost volume中的上下文信息的区域支持。 - 在KITTI上实现了最前沿的精确度。
…
3. Pyramid Stereo Matching Network 金字塔立体匹配网络
我们提出的PSMNet包含一个SPP模块和一个堆叠的hourglass模块,前者有效合并全局上下文,后者用于cost volume正则化。PSMNet的架构见Fig.1。
3.1 Network Architecture 网络架构
PSMNet的参数详见Table.1。与其他研究中第一卷积层应用大过滤器($7\times 7$)相比,三个小卷积过滤器($3\times 3$)以级联方式构建了一个具有相同感受野的更深的网络。conv1_x,conv2_x,conv3_x,conv4_x是基本的残差块,用于学习一元特征提取。对于conv3_x,conv4_x,应用扩张卷积(dilated convolution)以进一步扩大感受野。输出特征图大小是输入图像大小的$\frac{1}{4}\times \frac{1}{4}$,见Table.1。然后应用SPP模块(见Fig.1)收集上下文信息。我们将左右特征图堆叠到一个cost volume,然后被投入到3D CNN正则化。最后,应用回归计算输出视差图。SPP模块,cost volume,3D CNN,以及视差回归将在后面详细描述。
Table.1 PSMNet架构的参数。残差块的构建在括号中用堆叠块的数量指定,下采样由conv0_1,conv2_1执行,步长为2。BN和ReLU的使用遵循ResNet,但PSMNet在求和后不应用ReLU。$H$和$W$各表示输入图像的高和宽,$D$表示最大视差。
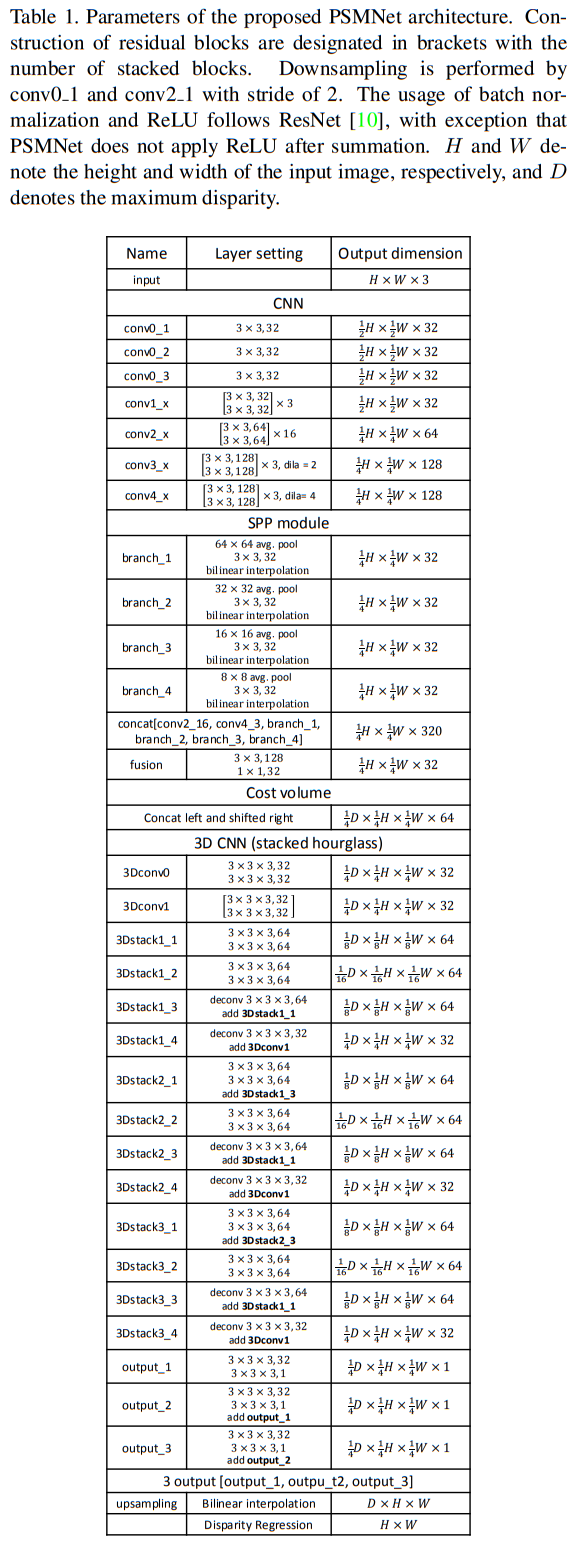
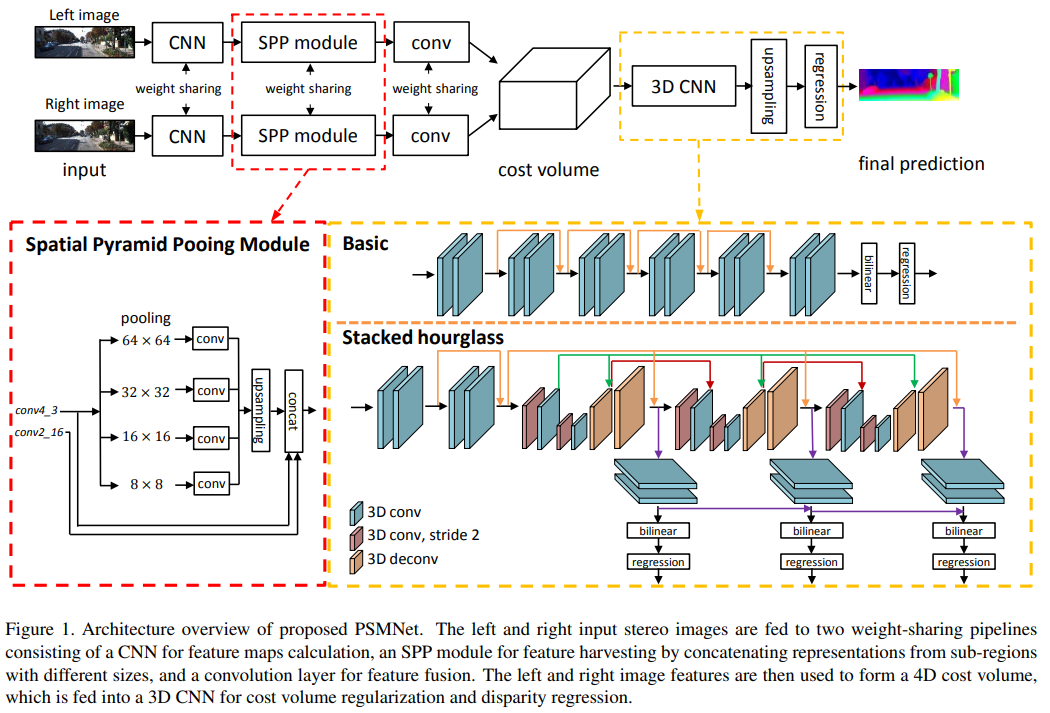
Fig.1 PSMNet的架构概述。左右输入的立体图像被投入两个权重共享的由CNN组成用于特征图计算的pipeline,SPP模块用于特征收集,通过连接来自不同大小的子区域的表示,以及用于特征融合的卷积层。然后左右图像特征组成一个4D的cost volume,并将其投入3D CNN用于cost volume的正则化和视差回归。
3.2. Spatial Pyramid Pooling Module 空间金字塔池化模块
仅从像素强度确定上下文关系是困难的,因此,具有丰富的目标上下文信息的图像特征可以有益于对应估计(correspondence estimation),特别是对于病态区域。在本工作中,目标(比如车)和子区域(窗户,轮胎,引擎盖等)之间的关系由SPP模块学习,以合并分层的上下文信息。
在[9]中,SPP被设计用于移除CNN中固定尺寸的限制,由SPP生成的不同层次(level)的特征图被展平并馈送到FC层中以进行分类,之后将SPP应用于语义分割问题。ParseNet应用全局平均池化以合并全局上下文信息,PSPNet[32]将ParseNet扩展到分层的全局先验,其包含具有不同尺度和子区域的信息。在[32]中,SPP模块使用自适应平均池化将特征压缩到4个尺度,后接$1\times 1$卷积降低特征维度,之后通过双线性插值(bilinear interpolation)将低维特征图上采样到与原特征图相同尺寸,不同级别的特征图堆叠起来作为最后的SPP特征图。
在当前的工作中,我们为SPP设计了4个固定尺寸的平均池化块:$64\times 64, 32\times 32, 16\times 16, 8\times 8$。见Fig.1和Table.1。进一步的操作,包括$1\times 1$卷积和上采样,和[32]一样。在消融研究(ablation study)中,我们进行了大量实验,以显示不同层次的特征图的效果,详述见4.2节。
3.3. Cost Volume
MC-CNN和GC-Net堆叠左右特征图使用深度网络来学习匹配成本估计(matching cost estimation),而不是使用距离度量。和GC-Net一样,我们通过在每个视差级别上连接左侧特征图和相应的右侧特征图采用SPP特征来形成cost volume,从而产生4D volume ($height\times width\times disparity\times feature size$)。
3.4. 3D CNN
SPP模块通过引入不同级别的特征促进立体匹配,为了聚合沿着视差维度和空间维度的特征信息,我们提出了两种3D CNN架构用于Cost Volume正则化:基本架构和堆叠的hourglass架构。在基本架构中(Fig.1),网络通过残差块简单构建,基本架构包含12个$3\times 3\times 3$的卷积层,然后我们通过双线性插值将cost volume上采样回到$H\times W\times D$的尺寸,最后我们使用回归来计算$H\times W$的视差图,这将会在3.5节中介绍。
为了学习更多的上下文信息,我们使用了堆叠的hourglass(编码-解码)架构,包含重复的自上而下/自下而上的处理以及中间监督(Fig.1)。堆叠的hourglass架构有三个主hourglass网络,每一个都生成视差图。也就是说,堆叠的hourglass架构有三个输出和损失(Loss_1, Loss_2, Loss_3)。损失函数在3.6节中描述。在训练阶段,总损失计算为三次损失的加权和。在测试阶段,最终的视差图是三个输出中的最后一个。在我们的消融实验中,基本架构用于评估SPP模块的性能,因为基本架构不会通过编码/解码过程学习额外的上下文信息。
3.5. Disparity Regression 视差回归
我们使用[13]中提出的视差回归来估计连续视差图。每个视差$d$的概率通过softmax操作$\sigma(·)$从预测成本$c_{d}$计算。预测的视差$\hat{d}$计算为通过其概率加权的每个视差$d$的总和,即:
$$ \hat{d}=\sum_{d=0}^{D_{max}} d\times \sigma(-c_{d}). \tag{1} $$
正如[13]中说的,上述视差回归比基于分类的视差匹配方法更具有鲁棒性。注意上述等式和[1]中介绍的相似,在那里它被成为软注意力机制。
3.6. Loss 损失
由于视察回归,我们采用smooth $L_{1}$损失函数训练提出的PSMNet,smooth $L_{1}$损失广泛用于目标检测的边界框回归,因为相比于$L_{2}$损失其鲁棒性和对异常值的低灵敏度。PSMNet的损失函数定义为
$$ L(d,\hat{d})=\frac{1}{N}\sum_{i=1}^{N}smooth_{L_{1}}(d_{i}-\hat{d}_{i}), \tag{2} $$
其中
$$ smooth_{L_{1}}(x)=\begin{cases} 0.5x^{2}, &if|x|<1 \\|x|-0.5, &otherwise\end{cases}, $$
其中$N$是标注像素的个数,$d$是gt视差,$\hat{d}$是预测视差。
…
References
[1] D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015. 5
[9] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In European Conference on Computer Vision, pages 346–361. Springer, 2014. 1, 3
[13] A. Kendall, H. Martirosyan, S. Dasgupta, P. Henry, R. Kennedy, A. Bachrach, and A. Bry. End-to-end learning of geometry and context for deep stereo regression. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017. 1, 2, 4, 5, 6, 7, 8
[32] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene parsing network. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017. 1, 2, 3, 4
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
…
2 DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
2.1 Convolutional Layers and Feature Maps
考虑流行的七层架构,前五个层是卷积层,其中一些后接池化层,这些池化层可以被认为是“卷积的”,在某种意义上它们使用滑动窗口。最后两层是FC层,伴随N路softmax作为输出,其中N是类别数量。
上述深度网络需要固定的图像大小,然而,我们注意到固定大小的需求仅由于FC层需要固定长度的向量作为输入,另一方面卷积层接受任意大小的输入。卷积层使用滑动过滤器,其输出和输入有大致相同的宽高比,这些输出被称为特征图,它们不仅涉及反映(responses)的强度,还涉及其空间位置。
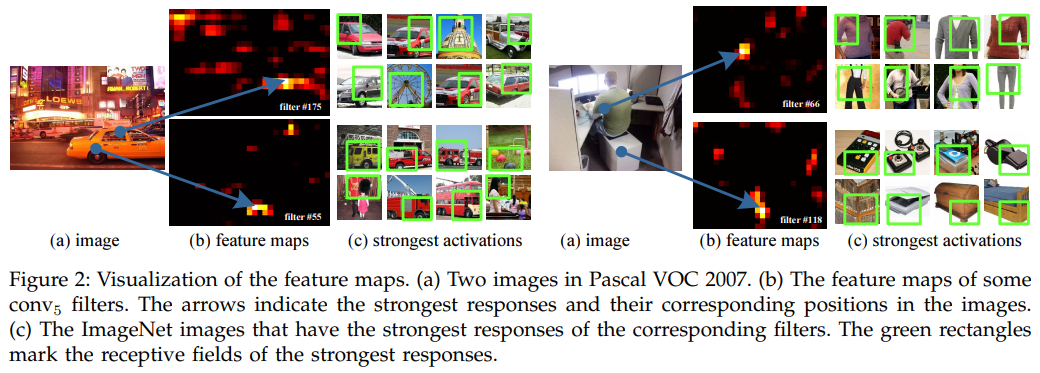
在Fig.2中,我们可视化了一些特征图,它们由conv5层的一些过滤器生成。Fig.2©显示了ImageNet数据集中这些过滤器最强的激活图像。我们发现过滤器会被一些语义内容激活,比如第55个过滤器(Fig.2 左下)最多被圆形激活;第66个过滤器(Fig.2 右上)最多被∧-形激活,第118个过滤器(Fig.2 右下)最多被V-形激活,输入图像中的这些形状(Fig.2(a))激活相应位置的特征图。
…
2.2 The Spatial Pyramid Pooling Layer
卷积层接受任意输入大小,但它们产生可变大小的输出,分类器(SVM/softmax)或FC层需要固定大小的向量,这种向量可以通过将特征汇集在一起的Bag-of-Words(BoW)方法生成,空间金字塔池化(SPP)改进了BoW,因为它能通过汇集(pool)局部的spatial bin来保持空间信息,这些spatial bin的大小与图像大小成正比,因此无论图像大小如何,bin的数量都是固定的,这与先前深度网络的滑动窗口池化相反,先前的池化是滑动窗口的数量取决于输入大小。
为了使用用于任意大小图像的深度网络,我们将最后的池化层(最后一个卷积层后面的pool5)替换为SPP层,见Fig.3。在每个spatial bin,我们汇集了(pool)每个过滤器的响应(在本文中我们使用最大池化),SPP的输出是$kM$维的向量,其中$M$表示bin的个数,$k$是最后一个卷积层的过滤器数量。固定维度的向量作为FC层的输入。
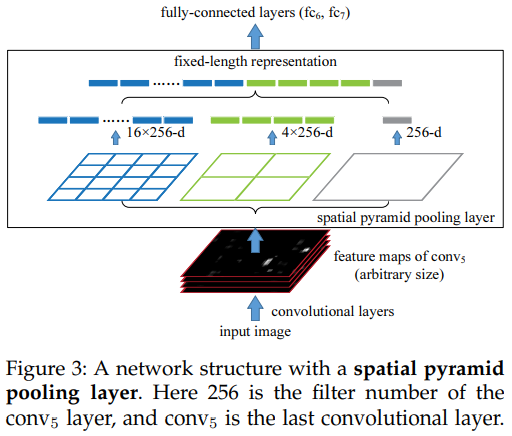
由于SPP,输入图像可以是任意大小,不仅允许任意宽高比,还允许任意尺寸。我们可以将输入图像调整到任意尺寸然后要用到同一个深度网络。…
有趣的是,最大的金字塔等级有一个覆盖整个图像的spatial bin,这事实上是”全局池化”操作,同样也在几个当前工作中被研究。全局平均池化用于降低模型大小和过拟合;在测试阶段,全局平均池化用于所有FC层之后以提高精确度;全局最大池化用于弱监督的目标识别。
…
文章作者 ling
上次更新 2019-09-29