YOLO:You Only Look Once
文章目录
1. Introduction
目前的检测系统用分类器来执行检测,为了检测一个目标,这些系统使用一个分类器在测试图片上的不同位置和尺寸上评估它。像DPM这样的系统使用一个滑动窗口,它会在整张图片的平均空间位置上运行。
更近的方法如R-CNN先使用候选区域方法生成图片中潜在的边界框,然后在这些边界框上运行分类器。分类后,后处理(post-processing)用于细化边界框,消除重复检测,并根据场景中其它目标重新调整边界框。这样复杂的流程又慢又难以优化,因为每个独立的组件都需要分别训练。
我们将目标检测问题重构为一个单独的回归问题,直接从像素到边界框坐标和类概率。使用我们的系统,You Only Look Once(YOLO) ,你只需看一次图片就能预测出有哪些目标、它们在哪儿。
YOLO相当简单:见图1。一个卷积网络同时预测多个边界框和这些框的类别概率。YOLO在完整的图片上训练,并直接优化检测性能。这种统一的模型相对传统目标检测方法有多种好处。

首先,YOLO非常快。因为我们将问题重构为回归问题,因此流程很简单。测试时我们只需要用我们的神经网络运行图片即可预测。我们的基础网络fps为45,快速版为150(无多进程,单Titan X)。这意味着我们能以低于25ms的延迟实时处理视频流。
其次,YOLO在预测时是基于整个图片推理的。不像基于滑动窗口和候选区域的技术,YOLO训练测试时有整个图片的视野,因此它隐式地将类的上下文信息和外观编码。而FRCN常将图片中的背景块误认为目标,因为它无法看到更大的上下文。相比FRCN,YOLO的背景错误要少一半。
最后,YOLO能学到目标的泛化表达。当在自然图片上训练而在艺术品上测试时,YOLO领先其它检测方法如DPM和R-CNN一大截。因为YOLO的高度泛化性,当应用在新领域和不同的输入时,更不容易失败。
2. Unified Detection
我们的系统将输入的图片分割为$S\times S$个网格(grid)。如果一个目标的中心落在一个网格单元中,该网格就负责检测这个目标。
每个网格单元预测B个边界框和边界框置信度。这些置信度得分反映了模型对框中包含目标的自信程度,以及框架对其预测的准确程度。我们将置信度定义为$P_{r}(object) * IOU_{pred}^{truth}$。如果网格单元不含目标,置信度分数应为0,否则我们希望置信度分数等于预测框和gt之间的IOU。
每个边界框包含5个预测值:(x,y,w,h,confidence),其中(x,y)表示相对于网格单元的边界框中心坐标,宽高(w,h)的预测值是相对整张图片而言的,置信度预测值(confidence)表示预测框与某一gt框的IOU。
每个网格单元预测C个条件类概率(conditional class probability),$P_{r}\left(Class_{i}|Object \right)$,这些概率以网格单元包含目标为条件。每个网格单元值预测一组类概率,而与预测框的数量B无关。
在测试时将条件类概率和单个框的置信度预测值相乘,
$$ P_{r}\left(Class_{i}|Object\right) * P_{r}(Object) * IOU_{pred}^{truth}=P_{r}\left(Class_{i}\right) * IOU_{pred}^{truth} \tag{1} $$
它为我们提供了每个框的特定类别的置信度分数,这些分数编码了某个类别出现在框中的可能性,以及预测框对目标的拟合程度。
在VOC上评估(evaluate)时,我们使用S=7,B=2,C=20(VOC有20个标签类),最后的预测结果是一个$7\times 7\times 30$的tensor。图2。
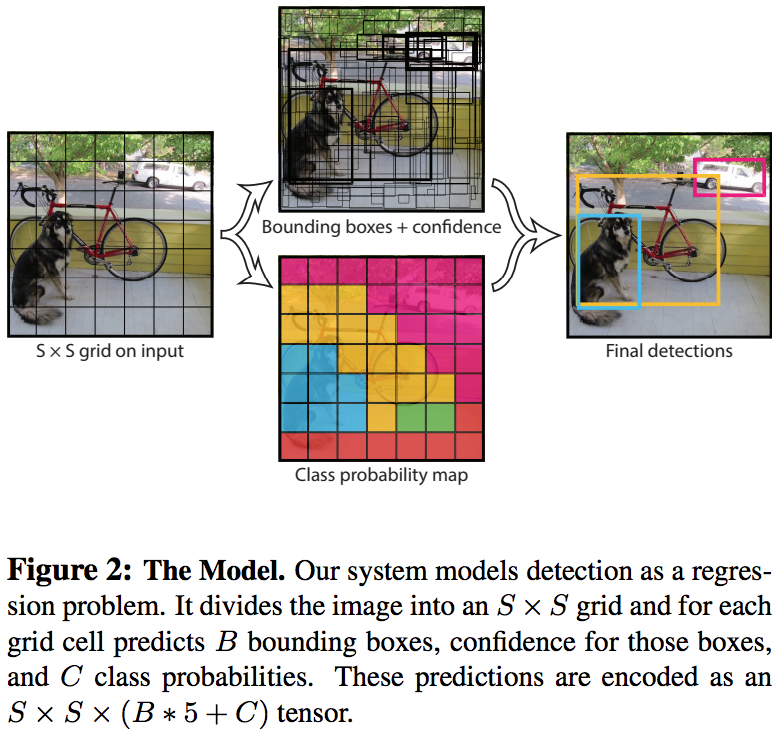
2.1 Network Design
我们将此模型实现成一个CNN并在VOC检测集评估它,conv层提取图片特征,fc层预测输出概率和坐标。
我们的网络结构灵感来自于用于图片分类的GoogLeNet,有24个conv层后接2个fc层,和GoogLeNet的inception模块不同,我们简单地使用了$1\times 1$的降维层(reduction layer)后接$3\times 3$的conv层。完整的网络结构如图3。

我们还训练了一个fast YOLO用来推进目标检测的速度边界,它的CNN有更少的conv层(9个而不是24个),每层有更少的过滤器,除了网络大小,Fast YOLO和YOLO的训练和测试参数均相同。
网络最后输出的预测值是一个$7\times 7\times 30$的tensor。
2.2 Training(训练)
我们在1000类的ImageNet竞赛集上预训练了卷积层,使用图3中的前20个conv层,后跟一个平均池化层和fc层,我们训练了约一周的时间,使其在ImageNet 2012验证集上单一裁剪图像top-5的准确率达到了88%,与Caffe模型池中的GoogLeNet模型相当。我们使用Darknet框架进行所有的训练和推断(training and inference)。
然后我们将模型用于检测,Ren提出在预训练网络后添加conv层和fc层能提高性能,因此,我们添加了权重随机初始化的4个conv层和2个fc层,检测通常需要更精确的视觉信息,所以我们将网络输入的分辨率从$224\times 224$增加到$448\times 448$。
最后一层同时预测类别概率和边界框坐标,我们用图像的宽高归一化边界框的宽高使其落在(0,1)之间,并将边界框中心坐标(x,y)参数化为特定网格单元位置的偏移量(offset)从而也限制在(0,1)。
我们对最后一层用了线性激活,其余层用如下的leaky relu激活:
$$ \phi(x)=\left\{\begin{array}{ll}{x,} & {\text { if } x>0} \\ {0.1x,} & {\text { otherwise }}\end{array}\right. \tag{2} $$
我们优化了输出的平方和误差(sum-squared error),我们使用平方和误差是因为它比较容易优化,然而它并不完全符合我们最大化平均精度的目标,使定位误差和分类误差的权重一样并不理想,并且每张图片都有大量的网格单元不含目标,这使得这些单元的置信度分数趋向0,过度影响(overpower)了包含目标的网格的梯度。这可能导致模型不稳定,使训练早期发散。
为了弥补这个问题,我们增加了来自边界框坐标预测的损失,降低了来自不含目标的边界框的置信度预测值的损失。我们用两个参数实现这一点,令$\lambda_{\text { coord }}=5 \text { and } \lambda_{\text { noobj }}=0.5$。
平方和误差同样为大边界框和小边界框给了同样的权重,我们的误差度量应该反映出大框的小偏差重要性不如小框。我们通过预测边界框的宽高的平方根代替直接的宽高在一定程度上改善这个问题。
YOLO为每个网格单元预测多个边界框,在训练阶段我们只希望一个边界框预测器为每个目标负责,我们选择与gt有最高IOU的边界框作为这个对预测结果“负责任的”预测器。这会导致边界框预测器之间的专业化,每个预测器在特定大小,长宽比或目标类别上表现更好,从而提高整体召回率。
在训练阶段,我们优化的多部分损失(multi-part loss)函数如下:
$$
\begin{array}{c}
{\lambda_{coord} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} \mathbb{1}_{ij}^{obj}\left[\left(x_{i}-\hat{x}_{i}\right)^{2}+\left(y_{i}-\hat{y}_{i}\right)^{2}\right]} \\
{+\lambda_{coord} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} \mathbb{1}_{ij}^{obj}\left[\left(\sqrt{w_{i}}-\sqrt{\hat{w}_{i}}\right)^{2}+\left(\sqrt{h_{i}}-\sqrt{\hat{h}_{i}}\right)^{2}\right]} \
{+\sum_{i=0}^{S^{2}} \sum_{j=0}^{B} \mathbb{1}_{ij}^{obj}\left(C_{i}-\hat{C}_{i}\right)^{2}} \\
{+\lambda_{noobj}\sum_{i=0}^{S^{2}} \sum_{j=0}^{B} \mathbb{1}_{ij}^{noobj}\left(C_{i}-\hat{C}_{i}\right)^{2}} \\
{+\sum_{i=0}^{S^{2}} \mathbb{1}_{i}^{obj} \sum_{c \in \text { classes }}\left(p_{i}©-\hat{p}_{i}©\right)^{2}} \tag{3}
\end{array}
$$
其中$\mathbb{1}_{i}^{obj}$表示目标是否出现在第i个单元,$\mathbb{1}_{ij}^{obj}$表示将第i个单元的第j个边界框作为需要“负责任的”的预测器。
注意如果目标存在与该网格单元中,损失函数才会惩罚分类误差(前面讨论的条件类别概率)。如果是对gt框“负责任的”预测器,它才会惩罚边界框坐标误差。
我们在VOC 2007和2012的训练集和验证集上训练了135个epoch。在2012上测试时,我们还引入了2007测试集进行训练。在整个训练中,mini-batch大小为64,动量为0.9,decay为0.0005。
我们学习率方案如下:在第一个epoch,我们缓慢地将学习率从$10^{−3}$提升到$10^{−2}$。如果从高学习率开始,模型常常因为不稳定的梯度而发散(diverge)。接着用$10^{−2}$训练75个epoch,接着$10^{−3}$进行30个epoch,最后30个epoch为$10^{−4}$。
为了避免过拟合,我们使用了dropout和数据增强。在第一个连接层后使用了rate=0.5的dropout层,防止层之间互相适应。对于数据增强我们引入了最高为原图大小的20%的随机缩放和转换(random scaling and translation)。我们还在HSV色彩空间中,用最高1.5的因子,随机的调整图像的曝光和饱和度。
2.3 Inference(测试)
就像训练一样,预测测试图像的检测只需要一次网络评估,在VOC上,网络为每张图像预测98个边界框,为每个边界框都预测类别概率。YOLO在测试时非常快因为它只需要一次网络评估,不像基于分类器的方法。
网格设计强化了边界框预测的空间多样性。通常一个目标落在哪个网格单元是很明显的,网络也只能为每个目标预测一个边界框。然而,一些大的目标或靠近多个单元边界的目标可以被多个单元很好地定位。非极大抑制(nms)可以用于解决多重检测,虽然nms对RCNN等网络的性能的影响不大,但给YOLO增加了2-3%的mA。
2.4 Limitations of YOLO(局限)
YOLO对于边界框预测强加了很强的空间约束,因为每个网格单元只能预测两个边界框和一个类别。这种空间约束限制了模型能预测到的邻近目标的数量,我们的模型很难应对成群出现的小目标,比如一群鸟。
由于我们的模型从数据中学习预测边界框,它很难泛化到新的目标或不寻常的比例或配置的目标。模型也是用相对粗糙的特征来预测边界框,因为模型的结构有来自输入图像的多个降采样层。
最后,当我们对近似于检测性能的损失函数训练时,损失函数会以相同的方式处理大边界框和小边界框的误差,大边界框的小误差通常是良性的,但是小边界框的小误差会对IOU造成很大的影响,我们主要的误差来源是不准确的定位。
3. Comparison to Other Detection Systems
…
4. Experiments
4.1 Comparison to Other Real-Time Systems
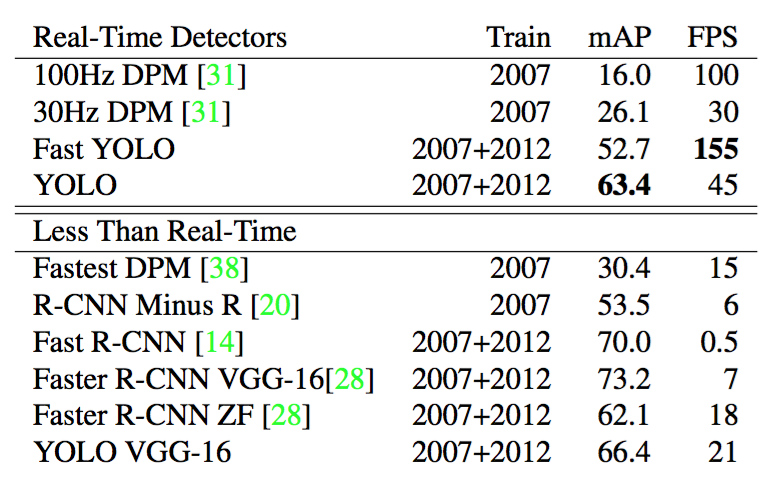
Fast YOLO是VOC上最快的检测方法;据我们所知,它是现有最快的目标检测器。它有52.7%的mAP,在实时检测上比前人成果的准确度高两倍,YOLO在保持实时性能的前提下把mAP推进到了63.4%。
我们还用了VGG-16训练YOLO,这个模型更准确,但比YOLO慢很多。将其用于与其它的基于VGG-16的系统进行比较很有用,但因为它的速度达不到实时检测,论文其余部分将着重于我们更快的模型。
近期的Faster R-CNN用神经网络替换SS来预测边界框。在测试中,他们最精确的模型达到了7fps,另一个更小,精度更低的版本达到了18fps。基于VGG-16版本的Faster R-CNN比YOLO 的mAP高10但是速度慢6倍,Zeiler-Fergus的Faster R-CNN仅比YOLO慢2.5倍,但它的精度也更低。
4.2. VOC 2007 Error Analysis
YOLO在正确地定位目标上有困难,定位错误占YOLO错误的大部分,比其他错误源加起来都多。Faster RCNN的定位错误更少但有较多的背景错误,也就是检测中不包含目标的假阳性,Faster RCNN比YOLO预测出背景的概率高3倍左右。
个人笔记
- 网络中含有fc层,因此在检测时YOLO只支持与训练图像相同的分辨率。
- 虽然每个格子可以预测B个边界框,但是最终只选择只选择IOU最高的边界框作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个,这是YOLO方法的一个缺陷。
- YOLO训练依赖于物体识别标注数据,同一类物体出现的新的不常见的长宽比和其他情况时,其泛化能力偏弱。
- YOLO的损失函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
文章作者 ling
上次更新 2019-09-01