YOLOv3
文章目录
…
2. The Deal
2.1 Bounding Box Prediction(边框预测)
根据YOLO9000的方法,系统使用维度集群作为anchor box来预测bounding box(边界框),网络为每个边界框预测4个坐标$(t_{x},t_{y},t_{w},t_{h})$。如果网格单元与图像左上角的偏移量为$(c_{x},c_{y})$,先验边界框的宽高分别为$p_{w},p_{h}$,则预测值为:
$$
\begin{aligned}
b_{x}=\sigma (t_{x})+c_{x} \
b_{y}=\sigma (t_{y})+c_{y} \
b_{w}=p_{w}e^{t_{w}} \
b_{h}=p_{h}e^{t_{h}}
\end{aligned}
$$
在训练时我们使用平方和误差损失,如果一些坐标预测值对应的gt为$\hat{t}_{*}$,梯度是gt值减去预测值:$\hat{t}_{*}-t_{*}$。该gt值很容易通过反转上述公式计算出。
YOLOv3用逻辑回归为每个边界框预测一个目标分数(objectness score, 判断有无目标)。如果先验边界框与一个gt的重叠度超过其它所有先验边界框,此目标分数应为1。如果先验边界框不是最好但与gt重叠度超过某一阈值,此预测值将被忽略,和Faster RCNN一样。我们将阈值设为0.5。与Faster RCNN不同的是,我们只为每个gt目标分配一个先验边界框。如果一个先验边界框没有被分配到gt目标,它不会导致坐标或类预测的损失,only objectness。
2.2 Class Prediction(类预测)
每个边框用多标签分类来预测边界框可能包含的类别,我们不使用softmax,因为它不是好的性能所必须的,取而代之我们仅使用独立的逻辑分类器。在训练时使用二分类交叉熵损失用于类预测。
当我们迁移到更复杂的领域时,比如Open Images Dataset,此方案会有所帮助。在这个数据集中有许多重叠的标签(比如Woman和Person),使用softmax强加了每个框仅有一个类别的假设,而事实并非如此。
2.3 Predictions Across Scale(多尺度预测)
YOLOv3以3种不同的尺度预测边框,我们的系统以这些尺度提取特征,与特征金字塔网络FPN(feature pyramid networks)的观念类似。我们为基本的特征提取器增加了几个conv层,其中最后一层输出一个3d tensor,编码了边界框,objectness和类预测。在我们的关于COCO数据集的实验中,我们在每个尺度上预测了3个边框,所以此tensor为$N*N*[3*(4+1+80)]$,表示4个边界框偏移量,1个objectness预测值,和80个类预测值。
然后我们提取两层前的特征图并对其进行2倍上采样,我们还提取了网络前面的某一层的特征图,将其与上采样的特征堆叠起来,此方法允许我们从上采样的特征和前面特征图里精细的特征得到更多有意义的语义信息。然后我们增加了一些conv层来处理组合的特征图,并最终输出类似的tensor,即使尺寸变为两倍。
我们再次执行相同的设计来为最后一个尺度预测边框,因此我们为第三个尺度的预测值受益于先前所有的计算和网络前面某层的精细特征。
我们同样使用k-means聚类来决定先验边界框,我们只是随意选择了9个簇和3个尺度,并将簇均匀分布到各尺度中。在COCO数据集中9个簇分别为:(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。
2.4 Feature Extractor(特征提取)
我们使用了一个新的网络来提取特征,该网络是Darknet19和ResNet的混合方案,相继使用了$3*3$和$1*1$的conv层,并增加了一些shortcut层,网络相当巨大,含有53个conv层,我们称其为Darknet53。
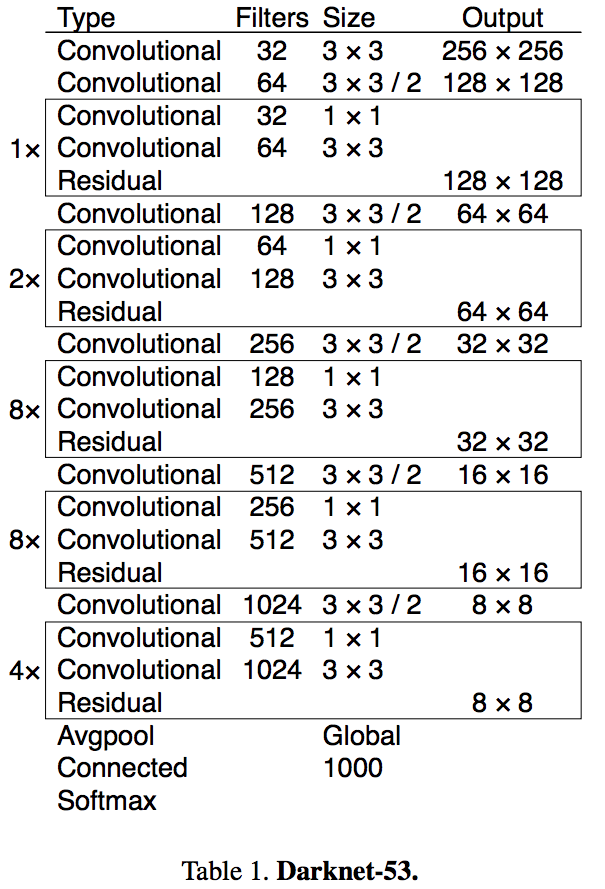
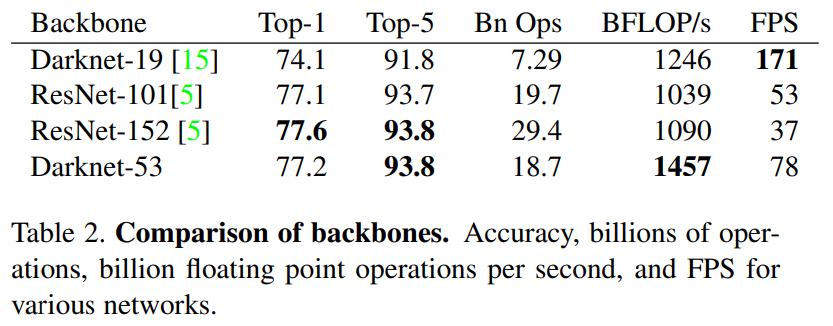
这个新网络比Darknet19更加强大,比Resnet101或Resnet152更加高效。ImageNet结果如下:
2.5 Training
我们仍在完整图像上训练,没有难例挖矿(hard negative mining),我们使用了多尺度训练,数据增强,bn等常规操作。
难例挖矿:正样本的数量远远小于负样本,这样训练出来的分类器的效果总是有限的,会出现许多false positive,把其中得分较高的false positive当做hard negative,既然mining出了这些Hard negative,就把这些扔进网络再训练一次,从而加强分类器判别假阳性的能力。
3. How We Do
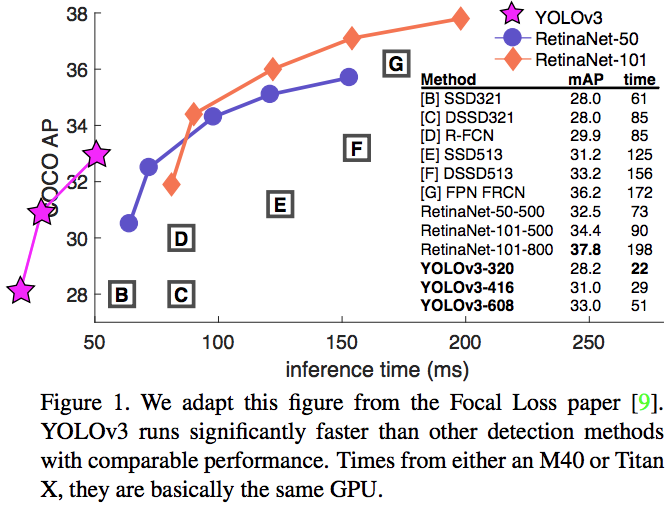
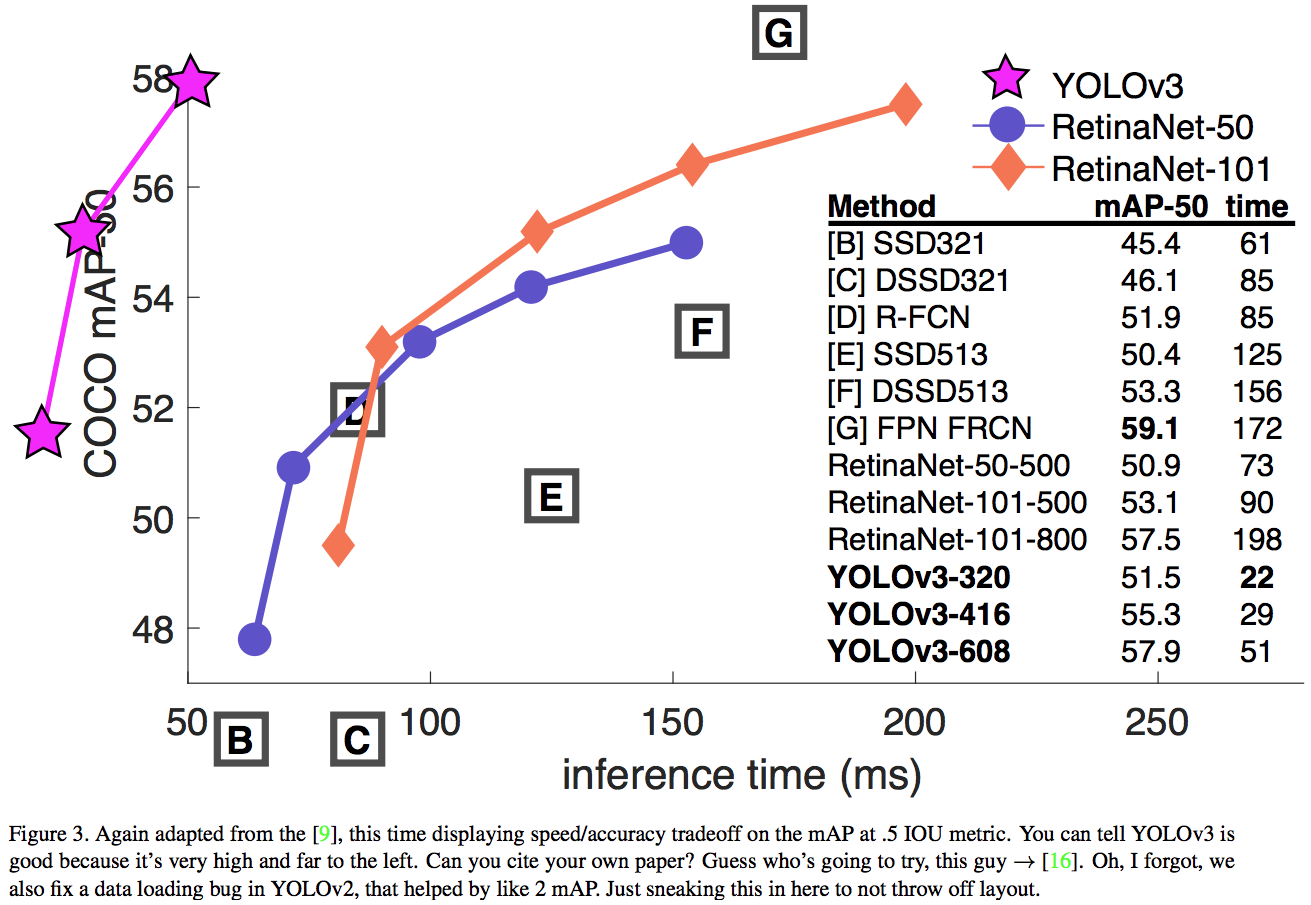
在COCO新的average mAP评价方法下,YOLOv3的性能与SSD变种相当但快3倍,仍落后于RetinaNet等模型。
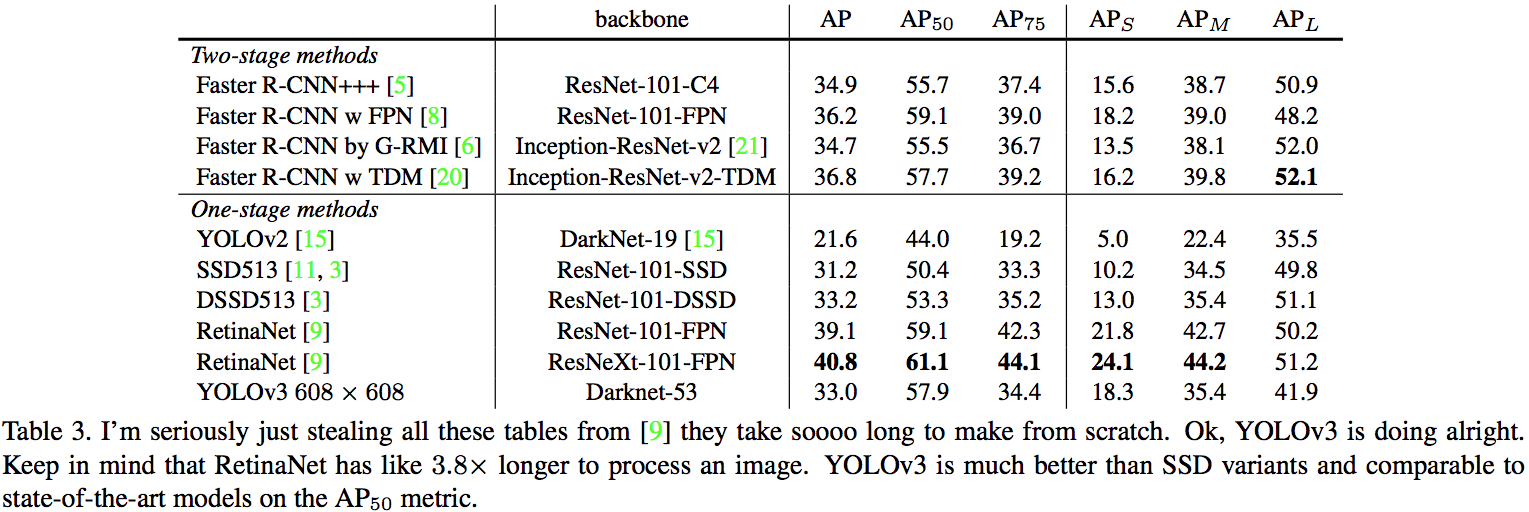
在旧mAP评价方法(IOU=0.5)下,YOLOv3非常强大,接近RetinaNet,远超SSD变种。这表明YOLOv3是一个非常强的检测器,擅长预测合适的边框,但当IOU阈值上升时性能大幅下降,说明它很难让边框与目标完美对齐。
过去YOLO难以处理小目标,现在有相反的趋势。使用新的多尺度预测,YOLOv3有着相对较高的AP性能,但是对于中大型目标,其性能相对较差。
当我们在$AP^{50}$上画出accuracy vs speed曲线时,我们发现YOLOv3明显好过其它系统,见图3。
$AP^{50}$: mAP at IOU=.50(VOC metric)
4. Things We Tried That Didn’t Work
…
Dual IOU thresholds and truth assignment(双IOU阈值和truth分配). Faster R-CNN在训练时使用了两个IOU阈值。如果预测框与gt的重叠度超过0.7,它被认为是正样本,[0.3-0.7]之间忽略,与所有gt目标都低于0.3的作为负样本。我们使用了类似策略但结果不佳。
…
文章作者 ling
上次更新 2019-09-09